ELYZA Japanese LLaMA 2 (CPU) を Chatbot UI から遊ぶ
先回記事の続きです。前回紹介した Elyza の日本語言語モデル ELYZA Japanese LLaMa 2 を Chatbot UI から使えるようにしてみました。
Llama.cpp の Python バインディングである llama-cpp-python は OpenAI 互換の API サーバーを内蔵しているので、ここに Chatbot UI を接続することで、ChatGPT のように WEB から ELYZA Japanese LLaMa 2 を使うことができます1。
検証環境
- MacBook Pro 14" (2023)
- Apple M2 Pro
- 16GB RAM
- macOS Ventura
仮想環境を切る
python3 -m venv venv
. ./venv/bin/activate
サーバープログラムの用意
仮想環境に llama-cpp-python をインストールします。[server] エクストラをつけてインストールする必要があります。
Llama.cpp 本体も含まれているので、別で用意する必要はありません。
pip3 install "llama-cpp-python[server]"
オリジナルの LLaMA 2 と Elyza モデルでは、プロンプトのフォーマットが異なるので、ソースコードを少し修正します。
仮想環境内の llama-cpp-python パッケージの llama_cpp/llama.py を以下のように書き換えます。
--- a/llama_cpp/llama.py
+++ b/llama_cpp/llama.py
@@ -1574,12 +1574,27 @@ class Llama:
stop = (
stop if isinstance(stop, list) else [stop] if isinstance(stop, str) else []
)
- chat_history = "".join(
- f'### {"Human" if message["role"] == "user" else "Assistant"}:{message["content"]}'
- for message in messages
- )
- PROMPT = chat_history + "### Assistant:"
- PROMPT_STOP = ["### Assistant:", "### Human:"]
+
+ B_INST, E_INST = " [INST] ", " [/INST] "
+ B_SYS, E_SYS = "<<SYS>>\n", "\n<</SYS>>\n\n"
+ chat_history = ""
+ for i, message in enumerate(messages):
+ if message["role"] == "system":
+ if i + 1 < len(messages) and messages[i + 1]["role"] == "user":
+ chat_history += B_INST + B_SYS + message["content"] + E_SYS
+ else:
+ chat_history += B_INST + B_SYS + message["content"] + E_SYS + E_INST
+ elif message["role"] == "user":
+ if i - 1 >= 0 and messages[i - 1]["role"] == "system":
+ chat_history += message["content"] + E_INST
+ else:
+ chat_history += B_INST + message["content"] + E_INST
+ else:
+ chat_history += message["content"]
+
+ PROMPT = chat_history
+ PROMPT_STOP = ["[end of text]", "### Assistant:", "### Human:"]
+
completion_or_chunks = self(
prompt=PROMPT,
stop=PROMPT_STOP + stop,
サーバー起動
--model オプションで gguf ファイルへのパスを指定して、API サーバーを起動します。
python3 -m llama_cpp.server --model ../ELYZA-japanese-Llama-2-7b-instruct-q5_K_M.gguf
外に公開する場合は、オプションに --host 0.0.0.0 を付けます。
http://localhost:8000/docs へアクセスして、FastAPI ではお馴染みの Swagger 画面が出ていれば起動できています。

WEB クライアントを用意する
Chatbot UI をクローンします。
git clone https://github.com/mckaywrigley/chatbot-ui.git
cd chatbot-ui
npm パッケージをインストールします。
npm i
環境変数ファイルを作成します。
cp .env.local.example .env.local
.env.local に、いくつか環境変数を設定する必要があります。以下のように OPENAI_API_HOST と OPENAI_API_KEY を設定します。本物の OPENAI_API_KEY を入れる必要はありません。SYSTEM_PROMPT や TEMPERATURE はお好みで指定して OK です。
# Chatbot UI
OPENAI_API_HOST="http://localhost:8000"
OPENAI_API_KEY=fake_key
NEXT_PUBLIC_DEFAULT_SYSTEM_PROMPT="あなたは誠実で優秀な日本人のアシスタントです。"
NEXT_PUBLIC_DEFAULT_TEMPERATURE=1
WEB フロントエンドを起動
Next.js の開発サーバーを起動します。
npm run dev
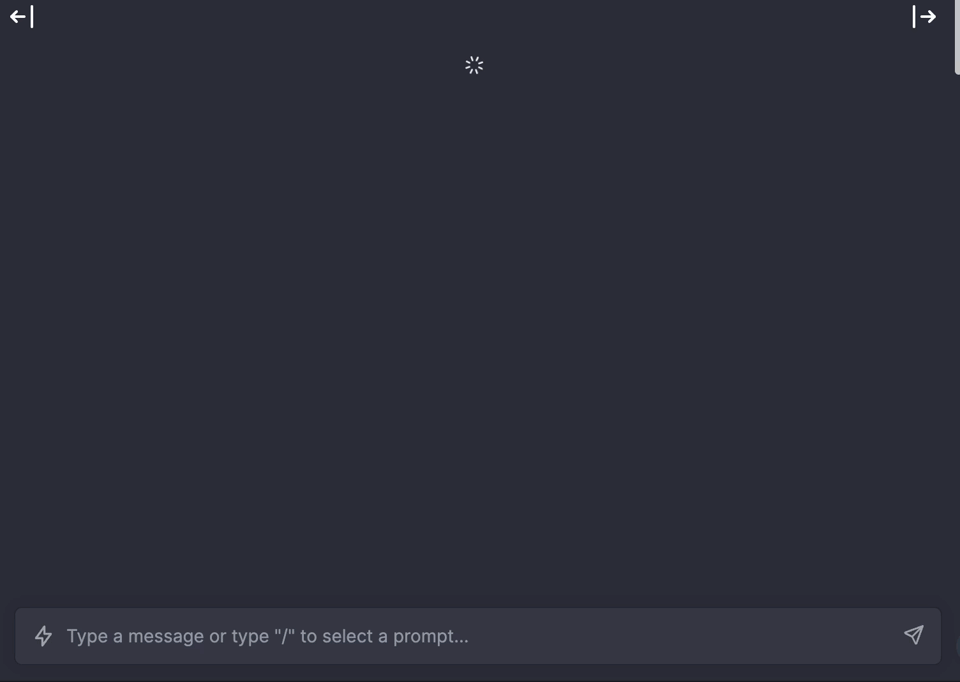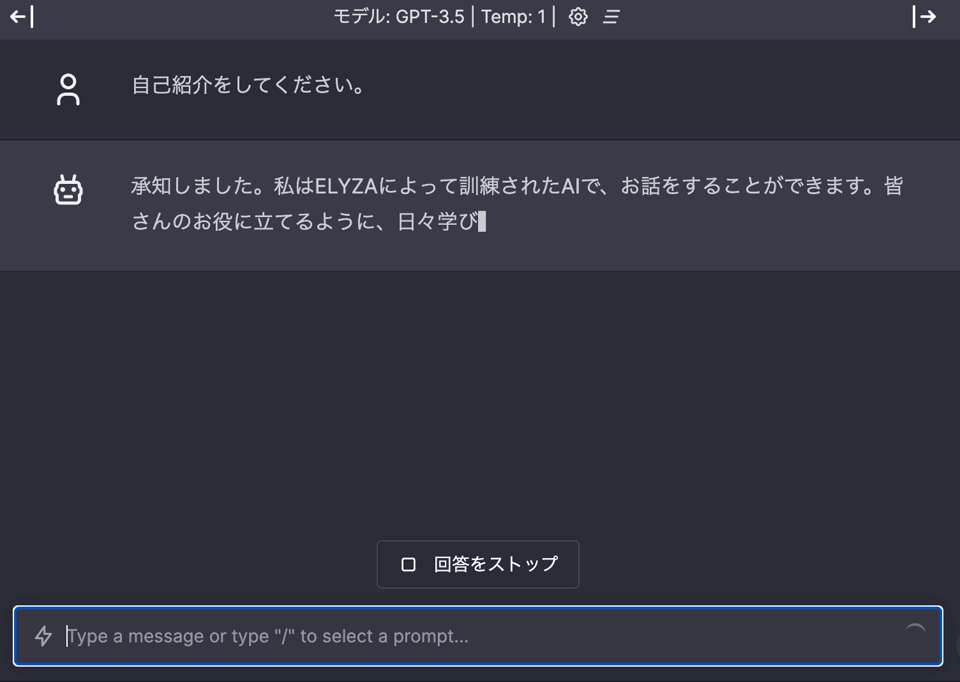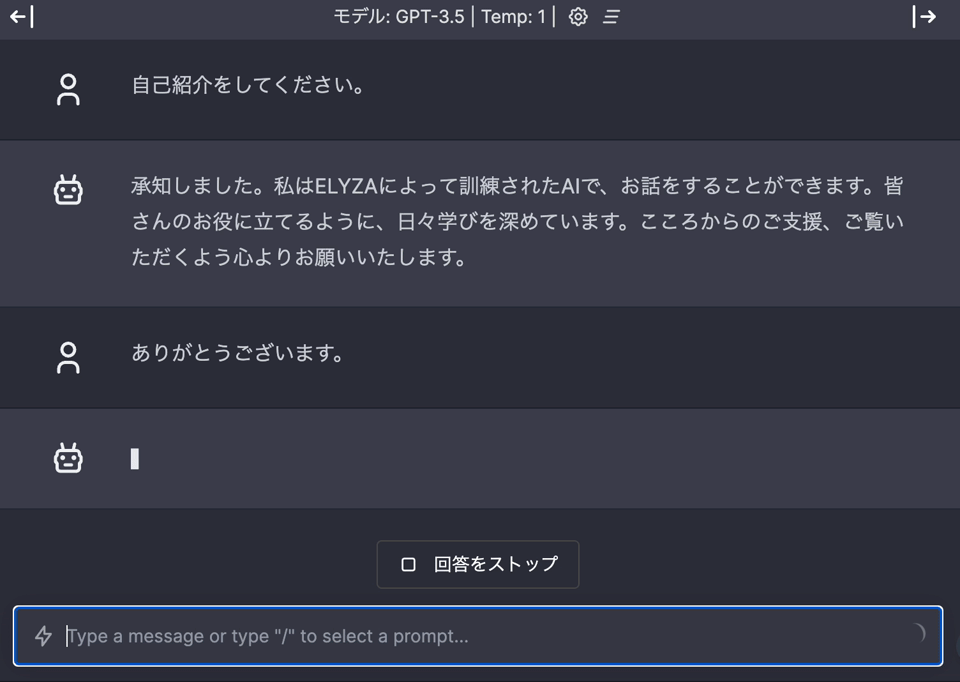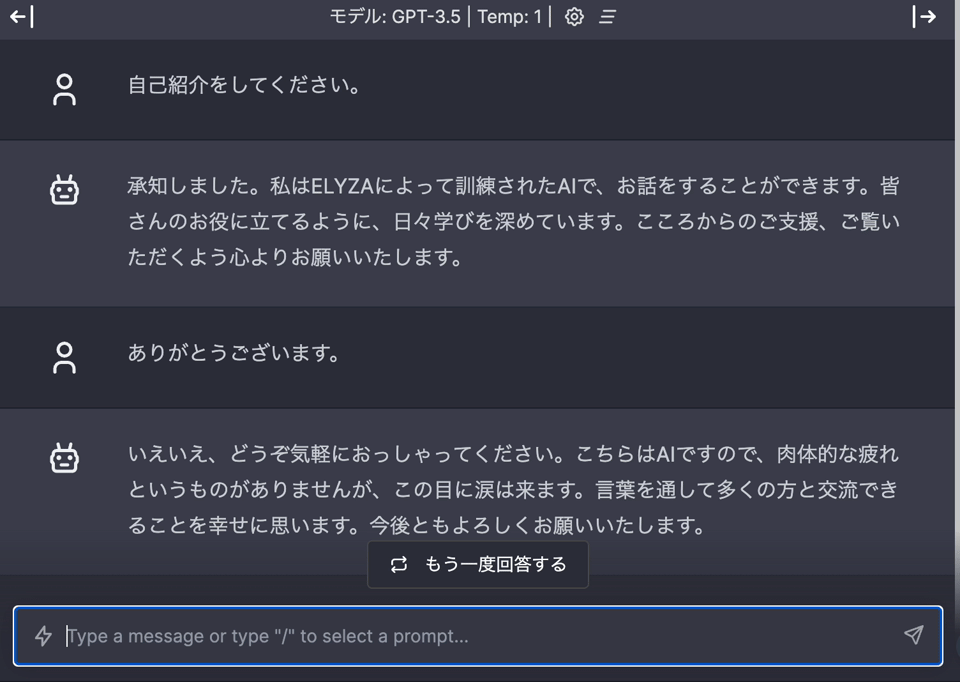
http://localhost:3000 にアクセスすると、以下のようにお話しができるようになっています。
プロンプトを探索するときは、WEB のほうがやりやすいと思うので、活用してみてください。

2024/01/27 追記
llama-cpp-python の内部が変わり、構築手順が一部簡単になりました。新しい構築手順は新しい 13B モデルの記事を見てください。
ただし、Chatbot UI は ChatGPT 前提で作られているので、一部 UI 表示におかしい点がでます。 ↩︎



