プリキュア StyleGAN を作った話 〜 其の壱
画像生成の主戦場はすっかり拡散モデルですが、大学時代に作成していた「プリキュア StyleGAN」を紹介します。プロフィールアイコン程度に使える画像の生成を目標としていました。
最終形態(この記事よりもさらに追加で改善を実施)のリポジトリは以下です。 Chainer で出来ているので、保守作業がやや面倒なことになっていますが、ちゃんと動くはずです。
大人の事情でプリキュアのウェイトは配れませんが(ここ最近の、なんでもモデルばら撒きたわけ状態には憂慮している)、オープンなデータセットで訓練したモデルは同梱しているので、すぐに試すことができます。
実写系のモデルは 256px 四方の画像を生成できます(MNIST もあるよ)。
Generative Adversarial Network (GAN)
GAN は生成器 (Generator) と識別器 (Discriminator) の競り合いによって訓練されます。 Generator は多次元乱数(基本的に正規分布)ベクトルを入力として偽データを生成します。 Discriminator はデータが本物であるかを判別する役割を負います。
Discriminator は本物データを偽物と、偽物データを本物と判断するほど、損失が増えるようになっています。以下は (Generator) と (Discriminator) の損失関数を表した式で、 は生成した偽データ、 は本物データを表します。 は本物だと思われる入力に対して大きな値を返そうとします。
一方、Generator は Discriminator が偽データを本物だと思い込むほど損失が小さくなります。
なお、これら損失関数を深層学習ライブラリで実装する際、 関数が定義されていれば、それを使うと良いです。
この損失関数定義に沿って学習することで、 は多次元正規分布から本物データへの写像を獲得し、乱数入力から本物のようなデータを生成するようになります。
学習の進め方
これら Discriminator と Generator の訓練は2つの誤差逆伝播フェーズの繰り返しで行われます。この誤差逆伝播による重み更新を交互(回数が非対称のモデルもある)に回すというのが GAN の特徴的な、かつ初めて学ぶ際に理解しにくい点の一つでもあります。
Discriminator 訓練時のデータの流れは以下のようになります。
--- title: Discriminator の訓練時 --- graph LR N(Random) G[Generator] D[Discriminator] R(Real) F(Fake) L(Loss) P(Prediction) T(Ground Truth) N --> G G --> F F --> D R --> D D --> P P --> L T --> L linkStyle 4,5 stroke:#31bec5,stroke-width:4px
先に見せた損失関数の通り、真贋データ両方に対して判別を実施しそれらの誤差を逆伝播させます1(図の青緑線の部分を逆伝播させ Discriminator を更新)。このとき、更新される重みは Discriminator のものだけで、Generator の重みは触りません。
Generator 訓練時のデータの流れは以下のようになります(図の青緑線の部分を逆伝播させ Generator を更新)。
--- title: Generator の訓練時 --- graph LR N(Random) G[Generator] D[Discriminator] F(Fake) L(Loss) P(Prediction) N --> G G --> F F --> D D --> P P --> L linkStyle 1,2,3,4 stroke:#31bec5,stroke-width:4px
Generator への逆伝播時に Discriminator も通過しますが、Discriminator のパラメータは更新されないように固定しておきます。
ちなみに、Generator は自身の生成物を Discriminator に通した結果からしか学ばないので、Generator の訓練時にはデータセットの内容は使われません。
StyleGAN
StyleGAN は、NVIDIA が 2019 年に発表した GAN の発展型です。 Progressive Growing2 するところ以外は、ネットワークアーキテクチャが工夫された普通の CNN-Based GAN と思ってもらってよいです。
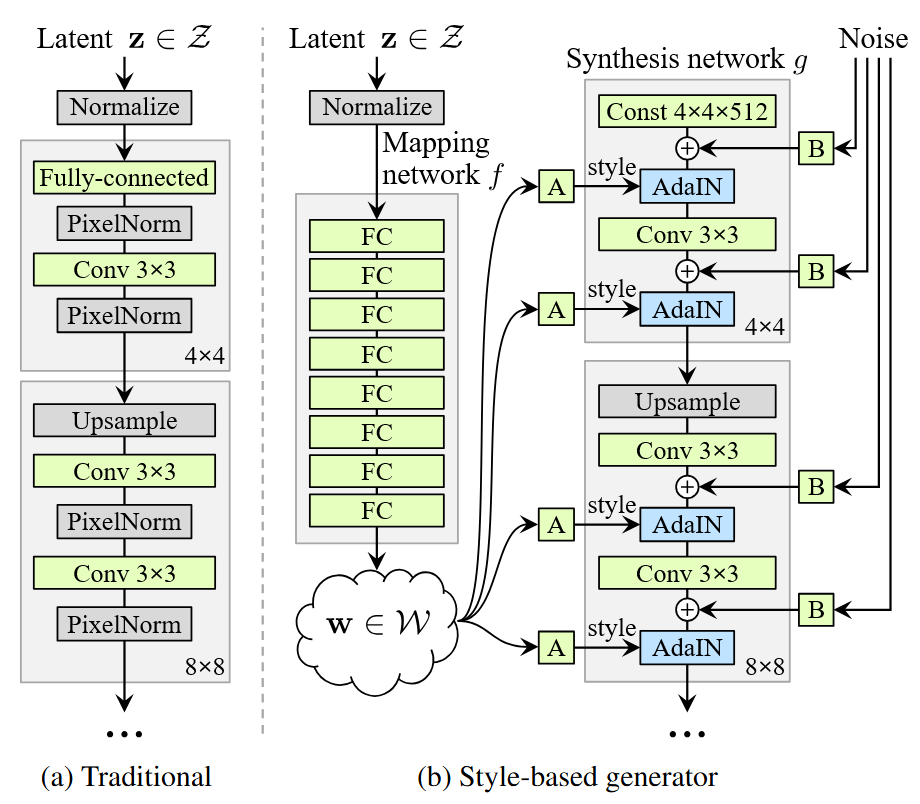
実装していると何度も見ることになる StyleGAN の Generator アーキテクチャ図(右)
Karras et al.3 からの図の引用で Generator のアーキテクチャを説明します。
図の (a) は普通の CNN-Based GAN の Generator アーキテクチャであり、徐々に特徴マップをアップスケールすることで解像度を上げていきます。
図の (b) は StyleGAN の Generator アーキテクチャであり、解像度を徐々に上げる過程を経る点は同じですが、入力乱数の扱い方が大きく異なります。 StyleGAN では、乱数を CNN へ直接渡すことはせず、まず (b) 中左の多層パーセプトロンでいくつかの「スタイル」を分解・抽出します。この「スタイルベクトル」はもとの乱数表現に比べ、抽象的概念のエンコーディングの直交性が良く(矛盾するような特徴量が作られにくくなる)、生成画像の不自然な点を減らすことができます。
スタイルベクトルは、畳み込み層間へスタイルを適用できる構造 AdaIN によって取り入れられ、各層でその都度生成を制御します。これにより、様々な解像度において特徴マップを効果的に誘導できます。例えば、粗い解像度の段階(画像の大枠)で適用されるスタイルベクトルは、髪の色や顔の形など全体的な特徴を決定します。一方で、細かい解像度の段階(出力層に近い方)で適用されるスタイルベクトルは、髪の毛の細かな束や、皮膚の質感、口内の色などを決定します。これにより、全体的な形状と局所的なディテールを分離して制御できるため、生成される画像の破綻感が緩和されます。各層に渡るスタイルベクトルは別々のものにすることもできるので (Style Mixing)、その場合は適用範囲を限定的に特徴を制御できます。
なお、StyleGAN では、Generator 全体に亘って各 AdaIN の前でランダムノイズを追加します。このノイズが、髪の質感や皮膚の反射のような微細なランダム変動を生み出し、リアルさの向上に寄与します(これらは、本質的にランダムであると思われるため)。

Style Mixing の例 - Karras et al.
上の表は Style Mixing の例です。 Source B のスタイルで、Source A を生成するスタイルの一部を特定層(複数可)において置換しています。下の方の行では、より出力層に近い方でスタイルの置換を行っているので、Source A の全体的な構造が維持されやすくなっていることが分かります。

Style Mixing の例 - プリキュア StyleGAN
上記は最終版のプリキュア StyleGAN のものですが、こちらも Style Mixing はうまくいきました。 Level の大きい方が出力層に近い層で、2-Mix の例だと、Level 1–4 の構造を維持しつつ、Level 5–7 テクスチャの合成ができていることがはっきり分かります(と、書いたんですが、どこからともなく別の口の形が適用されているので、特徴量の分離が完璧ではないようです)。
データセット
実装の話に戻ります。
プリキュアの画像データは、気合いでウェブから手作業で集めました。顔のランドマーク位置が画像毎で変動しないようにするために OpenCV で自動切り抜きをしています。
水増しのため、水平反転をかけたデータを追加するデータ拡張を実施しました。
水増し後のデータ総数は、約 2000 枚でした。
演算環境
ごく最初の頃は、GeForce GTX 960 で回していましたが(VRAM が 2 GB しかないが、ミニバッチサイズを 1 にすることでギリギリ学習できる)、その後は Google Colab の無料枠を活用したりしつつ、最終的には GeForce RTX 3090 が使えるようになったので、VRAM 量の恩恵を実感しつつ成果物の最終調整をしていました。
なんやかんやクラウドコンピューティングは面倒だし、物理マシンの開発体験は至高です。冬場は暖房代わりにもなります。
ちなみに、GeForce RTX 3090 といえど、完成版モデルの作成には 1〜2 週間計算し続ける必要があります。
成果物と結果
ここまで(拡張なし StyleGAN の学習)を実施したコードと生成結果が以下のリポジトリにまとまっています。
生成品質については、なんとも微妙な結果です。
当時 (2019) では、これが一番よさそうな(やりがい的にも)技術だったので実施しましたが、生成モデル評価指標の FID(小さいほど良い)は 80 であり、一桁がざらな論文結果と大きく乖離しています。使っているデータセットサイズが 30〜100 倍ほど違うので、当然ちゃ当然なのですが。
これでは満足できないので、生成品質を改善すべく StyleGAN 2.04 と Adaptive Discriminator Augmentation5 を導入します。次回へ続きます。
図では Ground Truth を見て Loss を計算するように書きましたが、Ground Truth は真偽の二項なので、実際には損失関数式の通り本物データと 由来のデータで別々に計算して足すように実装します。 ↩︎
Karras et al. Progressive Growing of GANs for Improved Quality, Stability, and Variation (2018). https://doi.org/10.48550/arXiv.1710.10196 ↩︎
Karras et al. A Style-Based Generator Architecture for Generative Adversarial Networks (2019). https://doi.org/10.48550/arXiv.1812.04948 ↩︎
Karras et al. Analyzing and Improving the Image Quality of StyleGAN (2020). https://doi.org/10.48550/arXiv.1912.04958 ↩︎
Karras et al. Training Generative Adversarial Networks with Limited Data (2020). https://doi.org/10.48550/arXiv.2006.06676 ↩︎





